转载自:https://zhuanlan.zhihu.com/p/630487962
但是本文的翻译使用AI进行了全文重新翻译,英文源自上文链接。
The Design of a Practical System for Fault-Tolerant Virtual Machines 中英文对照
ABSTRACT
We have implemented a commercial enterprise-grade system for providing fault-tolerant virtual machines, based on the approach of replicating the execution of a primary virtual machine (VM) via a backup virtual machine on another server. We have designed a complete system in VMware vSphere 4.0 that is easy to use, runs on commodity servers, and typically reduces performance of real applications by less than 10%. In addition, the data bandwidth needed to keep the primary and secondary VM executing in lockstep is less than 20 Mbit/s for several real applications, which allows for the possibility of implementing fault tolerance over longer distances. An easy-to-use, commercial system that automatically restores redundancy after failure requires many additional components beyond replicated VM execu- tion. We have designed and implemented these extra com- ponents and addressed many practical issues encountered in supporting VMs running enterprise applications. In this paper, we describe our basic design, discuss alternate design choices and a number of the implementation details, and provide performance results for both micro-benchmarks and real applications.
我们已经实施了一套基于商业级的企业级系统,用于提供容错虚拟机。该系统采用的方法是在另一台服务器上的备份虚拟机上复制主虚拟机(VM)的执行过程,从而实现容错功能。我们在VMware vSphere 4.0平台上设计了一个完整且易于使用的系统,它能在商用服务器上运行,并且通常使实际应用程序的性能降低不超过10%。此外,为了保持主虚拟机和备份虚拟机同步执行所需的数据带宽,在多个实际应用中仅为20 Mbit/s左右,这使得在更远距离下实现容错成为可能。
一套在故障后能自动恢复冗余的易用商业系统,除了需要复制虚拟机执行之外,还需要许多额外的组件。我们已经设计并实现了这些额外组件,并解决了在支持运行企业应用程序的虚拟机时遇到的许多实际问题。在本文中,我们将介绍我们的基本设计方案,讨论替代设计方案以及一些实现细节,并提供了微基准测试和实际应用的性能结果。
1. INTRODUCTION
A common approach to implementing fault-tolerant servers is the primary/backup approach [1], where a backup server is always available to take over if the primary server fails. The state of the backup server must be kept nearly identical to the primary server at all times, so that the backup server can take over immediately when the primary fails, and in such a way that the failure is hidden to external clients and no data is lost. One way of replicating the state on the backup server is to ship changes to all state of the primary, includ- ing CPU, memory, and I/O devices, to the backup nearly continuously. However, the bandwidth needed to send this state, particular changes in memory, can be very large.
一种实现容错服务器的常见方法是主备方法[1],在这种方法中,始终有一个备份服务器随时待命,在主服务器出现故障时接管工作。为了确保备份服务器能在主服务器故障时立即接手,并且对外部客户端隐藏这种故障,同时不丢失任何数据,必须时刻保持备份服务器的状态与主服务器几乎完全相同。其中一种复制主服务器状态到备份服务器的方法是对主服务器的所有状态变化(包括CPU、内存和I/O设备)进行近乎连续的传输。然而,发送这些状态所需带宽可能非常大,尤其是内存中的变化。
A different method for replicating servers that can use much less bandwidth is sometimes referred to as the state- machine approach [13]. The idea is to model the servers as deterministic state machines that are kept in sync by starting them from the same initial state and ensuring that they receive the same input requests in the same order. Since most servers or services have some operations that are not deterministic, extra coordination must be used to ensure that a primary and backup are kept in sync. However, the amount of extra information need to keep the primary and backup in sync is far less than the amount of state (mainly memory updates) that is changing in the primary.
有一种能够使用更少带宽的服务器复制的不同方法,有时被称为状态机方法[13]。其基本思想是将服务器建模为确定性状态机,通过使它们从相同的初始状态启动并确保接收到相同的请求输入且顺序一致,来保持同步。由于大多数服务器或服务都存在一些非确定性的操作,因此必须采用额外的协调机制以确保主服务器和备份服务器保持同步。然而,保持主服务器和备份服务器同步所需的额外信息量远小于主服务器中正在改变的状态(主要是内存更新)的信息量。
Implementing coordination to ensure deterministic execution of physical servers [14] is difficult, particularly as processor frequencies increase. In contrast, a virtual ma- chine (VM) running on top of a hypervisor is an excellent platform for implementing the state-machine approach. A VM can be considered a well-defined state machine whose operations are the operations of the machine being virtu- alized (including all its devices). As with physical servers, VMs have some non-deterministic operations (e.g. reading a time-of-day clock or delivery of an interrupt), and so extra information must be sent to the backup to ensure that it is kept in sync. Since the hypervisor has full control over the execution of a VM, including delivery of all inputs, the hypervisor is able to capture all the necessary information about non-deterministic operations on the primary VM and to replay these operations correctly on the backup VM.
实现对物理服务器[14]的协调以确保其确定性执行是一项困难的任务,特别是在处理器频率不断提高的情况下。相比之下,在hypervisor之上运行的虚拟机(VM)是实施状态机方法的理想平台。虚拟机可以被视为一个定义良好的状态机,其操作包括被虚拟化的机器(及其所有设备)的操作。与物理服务器一样,虚拟机也有一些非确定性操作(例如读取时间日期时钟或中断的传递),因此需要向备份发送额外信息以确保保持同步。由于hypervisor完全控制虚拟机的执行,包括所有输入的传递,因此它可以捕获关于主虚拟机上所有非确定性操作的所有必要信息,并能够在备份虚拟机上正确重播这些操作。
Hence, the state-machine approach can be implemented for virtual machines on commodity hardware, with no hard- ware modifications, allowing fault tolerance to be imple- mented immediately for the newest microprocessors. In ad- dition, the low bandwidth required for the state-machine approach allows for the possibility of greater physical sepa- ration of the primary and the backup. For example, repli- cated virtual machines can be run on physical machines dis- tributed across a campus, which provides more reliability than VMs running in the same building.
因此,状态机方法可以在商品硬件上的虚拟机上实现,无需对硬件进行任何修改,这使得最新微处理器能够立即实现容错功能。此外,状态机方法所需的低带宽使得主备份能够实现更大的物理隔离。例如,复制的虚拟机可以在校园内分布的不同物理机上运行,这比在同一栋建筑内运行的虚拟机提供了更高的可靠性。
We have implemented fault-tolerant VMs using the pri- mary/backup approach on the VMware vSphere 4.0 plat- form, which runs fully virtualized x86 virtual machines in a highly-efficient manner. Since VMware vSphere imple- ments a complete x86 virtual machine, we are automatically able to provide fault tolerance for any x86 operating sys- tems and applications. The base technology that allows us to record the execution of a primary and ensure that the backup executes identically is known as deterministic re- play [15]. VMware vSphere Fault Tolerance (FT) is based on deterministic replay, but adds in the necessary extra pro- tocols and functionality to build a complete fault-tolerant system. In addition to providing hardware fault tolerance, our system automatically restores redundancy after a failure by starting a new backup virtual machine on any available server in the local cluster. At this time, the production ver- sions of both deterministic replay and VMware FT support only uni-processor VMs. Recording and replaying the exe- cution of a multi-processor VM is still work in progress, with significant performance issues because nearly every access to shared memory can be a non-deterministic operation.
我们在VMware vSphere 4.0平台上采用主/备份方法实现了容错虚拟机(VMs),该平台以高度高效的方式运行完全虚拟化的x86虚拟机。由于VMware vSphere实现了一个完整的x86虚拟机,因此我们能够自动为任何x86操作系统和应用程序提供容错能力。支持我们记录主虚拟机执行并确保备份虚拟机执行一致的基础技术被称为确定性重播[15]。VMware vSphere容错(Fault Tolerance, FT)基于确定性重播技术,并添加了必要的额外协议和功能,构建出一个完整的容错系统。除了提供硬件容错外,我们的系统在故障发生后还能通过在本地集群中任何可用服务器上启动新的备份虚拟机来自动恢复冗余。
目前,确定性重播和VMware FT的生产版本仅支持单处理器虚拟机。对于多处理器虚拟机的执行记录与回放仍在进行中,由于几乎每一次对共享内存的访问都可能成为非确定性操作,这带来了显著的性能问题。
Bressoud and Schneider [3] describe a prototype implementation of fault-tolerant VMs for the HP PA-RISC plat- form. Our approach is similar, but we have made some fundamental changes for performance reasons and investi- gated a number of design alternatives. In addition, we have had to design and implement many additional components in the system and deal with a number of practical issues to build a complete system that is efficient and usable by customers running enterprise applications. Similar to most other practical systems discussed, we only attempt to deal with fail-stop failures [12], which are server failures that can be detected before the failing server causes an incorrect ex- ternally visible action.
Bressoud和Schneider在[3]中描述了一个针对HP PA-RISC平台的容错虚拟机(VM)的原型实现。我们的方法与其相似,但由于性能原因,我们对一些基础设计进行了根本性的改动,并研究了多种设计方案。此外,为了构建一个高效且适用于运行企业应用的客户使用的完整系统,我们不得不设计并实现系统中的许多附加组件,并处理一系列实际问题。与大多数其他讨论的实际系统类似,我们只尝试处理 fail-stop 故障[12],即在发生故障的服务器导致外部可见错误操作之前能够被检测到的服务器故障。
The rest of the paper is organized as follows. First, we describe our basic design and detail our fundamental proto- cols that ensure that no data is lost if a backup VM takes over after a primary VM fails. Then, we describe in de- tail many of the practical issues that must be addressed to build a robust, complete, and automated system. We also describe several design choices that arise for implementing fault-tolerant VMs and discuss the tradeoffs in these choices. Next, we give performance results for our implementation for some benchmarks and some real enterprise applications. Finally, we describe related work and conclude.
文章的剩余部分如下组织。首先,我们描述了我们基础的设计,并且详细说明了我们的基本协议,它能确保在主 VM 失败后,备份 VM 能够接替,且不会造成数据丢失。然后,我们描述了许多实际问题的细节,这些问题是为了建立一个健壮的、完整的和自动化系统过程中必须被处理的。我们也描述了几个可用于实现故障容忍 VMs 的设计选择,并且讨论了这些选择的得失。接着,我们给出在一些基准以及实际企业级应用上的性能结果。最后,我们描述相关的工作和结论。
2. BASIC FT DESIGN
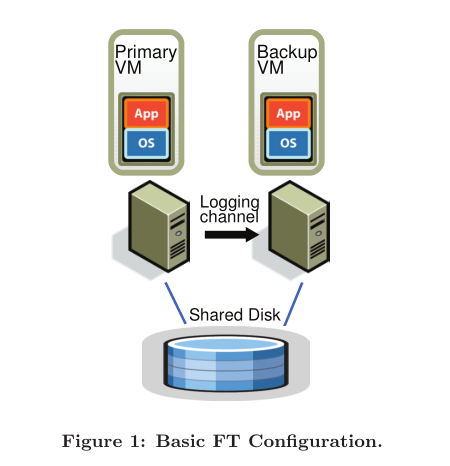
Figure 1 shows the basic setup of our system for fault- tolerant VMs. For a given VM for which we desire to provide fault tolerance (the primary VM), we run a backup VM on a different physical server that is kept in sync and executes identically to the primary virtual machine, though with a small time lag. We say that the two VMs are in virtual lock- step. The virtual disks for the VMs are on shared storage (such as a Fibre Channel or iSCSI disk array), and there- fore accessible to the primary and backup VM for input and output. (We will discuss a design in which the primary and backup VM have separate non-shared virtual disks in Sec- tion 4.1.) Only the primary VM advertises its presence on the network, so all network inputs come to the primary VM. Similarly, all other inputs (such as keyboard and mouse) go only to the primary VM.
图1展示了我们为容错虚拟机(VM)设计的基本配置。对于需要提供容错保护的目标VM(即主VM),我们在不同的物理服务器上运行一个备份VM,使其与主虚拟机保持同步,并以较小的时间延迟执行完全相同的指令。我们将这两个VM称为处于“虚拟锁步”状态。VM的虚拟磁盘位于共享存储(例如光纤通道或iSCSI磁盘阵列)上,因此主VM和备份VM都可以访问这些虚拟磁盘进行输入和输出操作。(我们将在第4.1节讨论一种主VM和备份VM拥有各自独立且非共享虚拟磁盘的设计方案。)只有主VM在网络中公开其存在,因此所有网络输入都指向主VM。同样,所有其他输入(如键盘和鼠标)也只发送给主VM。
All input that the primary VM receives is sent to the backup VM via a network connection known as the logging channel. For server workloads, the dominant input traffic is network and disk. Additional information, as discussed below in Section 2.1, is transmitted as necessary to ensure that the backup VM executes non-deterministic operations in the same way as the primary VM. The result is that the backup VM always executes identically to the primary VM. However, the outputs of the backup VM are dropped by the hypervisor, so only the primary produces actual outputs that are returned to clients. As described in Section 2.2, the primary and backup VM follow a specific protocol, including explicit acknowledgments by the backup VM, in order to ensure that no data is lost if the primary fails.
所有主虚拟机接收到的输入都会通过一个称为“日志通道”的网络连接发送到备份虚拟机。对于服务器工作负载,最主要的输入流量来自于网络和磁盘。如第2.1节中将进一步讨论的,为了确保备份虚拟机与主虚拟机以相同方式执行非确定性操作,会按需传输额外信息。结果是备份虚拟机始终与主虚拟机完全一致地执行。然而,由备份虚拟机产生的输出会被虚拟机监控程序丢弃,因此只有主虚拟机会产生实际输出并返回给客户端。如第2.2节所述,主虚拟机和备份虚拟机遵循特定协议,包括备份虚拟机明确确认,目的是确保在主虚拟机出现故障时不会丢失任何数据。
To detect if a primary or backup VM has failed, our sys- tem uses a combination of heartbeating between the relevant servers and monitoring of the traffic on the logging channel. In addition, we must ensure that only one of the primary or backup VM takes over execution, even if there is a split- brain situation where the primary and backup servers have lost communication with each other.
为了检测主虚拟机或备份虚拟机是否出现故障,我们的系统采用了一种结合心跳机制的方法,即在相关服务器之间进行心跳通信,并监控日志通道上的流量。另外,我们必须确保即使在“脑裂”(split-brain)情况下,即主服务器和备份服务器相互间通信中断,也只会有一个主虚拟机或备份虚拟机接管执行任务。
In the following sections, we provide more details on sev- eral important areas. In Section 2.1, we give some details on the deterministic replay technology that ensures that pri- mary and backup VMs are kept in sync via the information sent over the logging channel. In Section 2.2, we describe a fundamental rule of our FT protocol that ensures that no data is lost if the primary fails. In Section 2.3, we describe our methods for detecting and responding to a failure in a correct fashion.
在接下来的章节中,我们将针对几个重要领域提供更多的详细信息。在2.1节中,我们将给出一些关于确定性重播技术的详细内容,该技术通过日志通道发送的信息确保主虚拟机和备份虚拟机保持同步。在2.2节中,我们将描述我们FT协议的一个基本原则,该原则确保在主节点出现故障时不会丢失任何数据。在2.3节中,我们将介绍我们用于正确检测和响应故障的方法。
2.1 Deterministic Replay Implementation
As we have mentioned, replicating server (or VM) exe- cution can be modeled as the replication of a determinis- tic state machine. If two deterministic state machines are started in the same initial state and provided the exact same inputs in the same order, then they will go through the same sequences of states and produce the same outputs. A vir- tual machine has a broad set of inputs, including incoming network packets, disk reads, and input from the keyboard and mouse. Non-deterministic events (such as virtual in- terrupts) and non-deterministic operations (such as reading the clock cycle counter of the processor) also affect the VM’s state. This presents three challenges for replicating execu- tion of any VM running any operating system and workload: (1) correctly capturing all the input and non-determinism necessary to ensure deterministic execution of a backup vir- tual machine, (2) correctly applying the inputs and non- determinism to the backup virtual machine, and (3) doing so in a manner that doesn’t degrade performance. In addition, many complex operations in x86 microprocessors have undefined, hence non-deterministic, side effects. Capturing these undefined side effects and replaying them to produce the same state presents an additional challenge.
如我们先前所述,复制服务器(或虚拟机)的执行可以被建模为确定性状态机的复制过程。若两个确定性状态机在相同的初始状态下启动,并按照相同的顺序接收到完全相同的输入,则它们将经历相同的状态序列并产生相同的输出。虚拟机有一系列广泛的输入,包括网络传入数据包、磁盘读取操作以及键盘和鼠标输入。非确定性事件(例如虚拟中断)和非确定性操作(例如读取处理器的时钟周期计数器)也会影响虚拟机的状态。这给运行任意操作系统和工作负载的任何虚拟机执行的复制带来了三个挑战:
- 正确捕获所有必要的输入和非确定性因素,以确保备份虚拟机的确定性执行;
- 将这些输入和非确定性因素正确地应用于备份虚拟机;
- 在不影响性能的前提下完成以上操作。
另外,在x86微处理器中,许多复杂的操作具有未定义的、因此是非确定性的副作用。捕获这些未定义的副作用并重放以生成相同状态是一项额外的挑战。
VMware deterministic replay [15] provides exactly this functionality for x86 virtual machines on the VMware vSphere platform. Deterministic replay records the inputs of a VM and all possible non-determinism associated with the VM execution in a stream of log entries written to a log file. The VM execution may be exactly replayed later by reading the log entries from the file.
For non-deterministic operations, sufficient information is logged to allow the operation to be reproduced with the same state change and output. For non-deterministic events such as timer or IO completion interrupts, the exact instruction at which the event occurred is also recorded. During replay, the event is delivered at the same point in the instruction stream. VMware determinis- tic replay implements an efficient event recording and event delivery mechanism that employs various techniques, includ- ing the use of hardware performance counters developed in conjunction with AMD [2] and Intel [8].
VMware确定性重播[15]在VMware vSphere平台上为x86虚拟机提供了这样的功能。确定性重播会记录虚拟机的输入以及与虚拟机执行相关的所有可能非确定性因素,并以日志条目的形式写入日志文件中。通过从文件中读取日志条目,可以精确地回放后来的虚拟机执行过程。
对于非确定性操作,将记录足够的信息以确保该操作能够在相同的状态变化和输出下被重现。对于诸如定时器或IO完成中断等非确定性事件,还会记录事件发生的准确指令位置。在重播期间,该事件将在指令流中的同一位置交付。VMware确定性重播实现了一种高效的事件记录和事件交付机制,采用了多种技术手段,包括与AMD[2]和Intel[8]合作开发的硬件性能计数器的使用。
Bressoud and Schneider [3] mention dividing the execution of VM into epochs, where non-deterministic events such as interrupts are only delivered at the end of an epoch. The no- tion of epoch seems to be used as a batching mechanism be- cause it is too expensive to deliver each interrupt separately at the exact instruction where it occurred. However, our event delivery mechanism is efficient enough that VMware deterministic replay has no need to use epochs. Each inter- rupt is recorded as it occurs and efficiently delivered at the appropriate instruction while being replayed.
Bressoud和Schneider[3]提到将虚拟机(VM)的执行划分为多个时期(epochs),其中非确定性事件(如中断)只在每个时期的末尾进行传递。时期的概念在这里似乎被用作一种批量处理机制,因为如果在中断发生的精确指令位置分别交付每个中断,成本会过高。然而,我们的事件传递机制足够高效,以至于VMware确定性重放技术无需使用时期(epochs)。在重放过程中,每当发生中断时都会记录下来,并且能够在适当指令处高效地进行交付。
2.2 FT Protocol
For VMware FT, we use deterministic replay to produce the necessary log entries to record the execution of the pri- mary VM, but instead of writing the log entries to disk, we send them to the backup VM via the logging channel. The backup VM replays the entries in real time, and hence executes identically to the primary VM. However, we must augment the logging entries with a strict FT protocol on the logging channel in order to ensure that we achieve fault tolerance. Our fundamental requirement is the following:
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is en- tirely consistent with all outputs that the pri- mary VM has sent to the external world.
对于VMware FT,我们使用确定性重播技术来生成必要的日志条目,以记录主虚拟机的执行过程。但与将日志条目写入磁盘不同的是,我们将这些条目通过日志通道发送给备份虚拟机。备份虚拟机实时重放这些条目,因此其执行过程与主虚拟机完全一致。然而,为了确保实现容错功能,我们必须在日志通道上增加严格的FT(Fault Tolerance)协议,对日志条目进行增强。
输出要求:如果在主虚拟机发生故障后,备份虚拟机接管执行,那么备份虚拟机将以一种与主虚拟机向外部世界发送的所有输出完全一致的方式继续执行。
Note that after a failover occurs (i.e. the backup VM takes over after the failure of the primary VM), the backup VM will likely start executing quite differently from the way the primary VM would have continued executing, because of the many non-deterministic events happening during execution. However, as long as the backup VM satisfies the Output Re- quirement, no externally visible state or data is lost during a failover to the backup VM, and the clients will notice no interruption or inconsistency in their service.
请注意,在 failover(即备份虚拟机在主虚拟机故障后接管)发生后,由于执行期间发生的许多非确定性事件,备份虚拟机的执行方式很可能与主虚拟机原本的执行方式大不相同。然而,只要备份虚拟机满足输出需求,在向备份虚拟机进行故障转移的过程中,外部可见的状态或数据就不会丢失,并且客户端将不会察觉到服务中断或不一致的情况。
For VMware FT, we use deterministic replay to produce the necessary log entries to record the execution of the pri- mary VM, but instead of writing the log entries to disk, we send them to the backup VM via the logging channel. The backup VM replays the entries in real time, and hence executes identically to the primary VM. However, we must augment the logging entries with a strict FT protocol on the logging channel in order to ensure that we achieve fault tolerance. Our fundamental requirement is the following:
Output Requirement: if the backup VM ever takes over after a failure of the primary, the backup VM will continue executing in a way that is entirely consistent with all outputs that the pri- mary VM has sent to the external world.
对于VMware FT,我们使用确定性重播技术来生成必要的日志条目,以记录主虚拟机(VM)的执行过程。但是,我们并不将这些日志条目写入磁盘,而是通过日志通道将它们发送给备份VM。备份VM实时重播这些条目,因此其执行与主VM完全一致。然而,为了确保达到容错效果,我们必须在日志通道上增加严格的FT协议来增强日志条目。
输出要求:如果主VM发生故障后由备份VM接管,备份VM将继续执行,并且其执行结果将与主VM之前发送给外部世界的全部输出保持完全一致。
The Output Requirement can be ensured by delaying any external output (typically a network packet) until the backup VM has received all information that will allow it to replay execution at least to the point of that output operation. One necessary condition is that the backup VM must have received all log entries generated prior to the output oper- ation. These log entries will allow it to execute up to the point of the last log entry. However, suppose a failure were to happen immediately after the primary executed the out- put operation. The backup VM must know that it must keep replaying up to the point of the output operation and only “go live” (stop replaying and take over as the primary VM, as described in Section 2.3) at that point. If the backup were to go live at the point of the last log entry before the output operation, some non-deterministic event (e.g. timer interrupt delivered to the VM) might change its execution path before it executed the output operation.
输出需求可通过推迟任何外部输出(通常指网络数据包)的发送来得到保障,直到备份虚拟机接收到所有必要的信息,确保其至少能够回放到该输出操作执行时刻为止。首要条件是,在执行输出操作之前生成的所有日志条目都必须已被备份虚拟机接收。这些日志条目将使得备份虚拟机能顺利执行至最近一条日志记录对应的执行点。然而,设想一种情况:在主虚拟机执行完输出操作后立刻发生了故障。在这种情况下,备份虚拟机必须明确知晓它需要持续进行回放,直至达到该输出操作执行的准确时间点,并且仅在此时“实时切换”(停止回放并如第2.3节所述接手成为主虚拟机)。如果备份虚拟机在输出操作前的最后一条日志记录处就实时切换,则在其执行到输出操作之前,某些非确定性事件(例如送达给虚拟机的定时器中断)可能会改变其原本的执行路径。
Given the above constraints, the easiest way to enforce the Output Requirement is to create a special log entry at each output operation. Then, the Output Requirement may be enforced by this specific rule:
Output Rule: the primary VM may not send an output to the external world, until the backup VM has received and acknowledged the log en- try associated with the operation producing the output.
鉴于上述限制,实现输出要求的最简单方法是在每个输出操作时创建一个特殊的日志条目。这样,可以通过以下特定规则来强制执行输出要求:
输出规则:主虚拟机(VM)在备份虚拟机接收到并确认与产生该输出的操作相关的日志条目之前,不得向外部世界发送任何输出。
If the backup VM has received all the log entries, includ- ing the log entry for the output-producing operation, then the backup VM will be able to exactly reproduce the state of the primary VM at that output point, and so if the pri- mary dies, the backup will correctly reach a state that is consistent with that output. Conversely, if the backup VM takes over without receiving all necessary log entries, then its state may quickly diverge such that it is inconsistent with the primary’s output. The Output Rule is in some ways analogous to the approach described in [11], where an “ex- ternally synchronous” IO can actually be buffered, as long as it is actually written to disk before the next external communication.
如果备份VM已经接收到所有日志条目,包括产生输出操作的日志条目,那么备份VM将能够精确地再现主VM在该输出点的状态。因此,如果主VM宕机,备份VM将会正确地达到与该输出一致的状态。相反,如果备份VM在未接收到所有必要日志条目的情况下接管,那么其状态可能会迅速偏离,导致与主VM的输出不一致。输出规则在某种程度上类似于[11]中描述的方法,其中“外部同步”的IO实际上可以被缓冲,只要它在下一次外部通信之前真正写入磁盘即可。
Note that the Output Rule does not say anything about stopping the execution of the primary VM. We need only delay the sending of the output, but the VM itself can con- tinue execution. Since operating systems do non-blocking network and disk outputs with asynchronous interrupts to indicate completion, the VM can easily continue execution and will not necessarily be immediately affected by the delay in the output. In contrast, previous work [3, 9] has typically indicated that the primary VM must be completely stopped prior to doing an output until the backup VM has acknowl- edged all necessary information from the primary VM.
请注意,输出规则并未提及停止主虚拟机(VM)的执行。我们只需要延迟输出发送,但虚拟机本身可以继续执行。由于操作系统通常使用异步中断来指示完成非阻塞网络和磁盘输出,因此虚拟机可以轻松地继续执行,并不一定立即受到输出延迟的影响。相比之下,先前的研究[3, 9]通常表明,在主虚拟机进行输出之前必须完全停止其运行,直到备份虚拟机已从主虚拟机确认所有必要的信息为止。
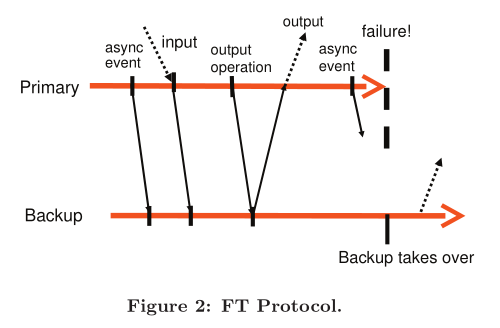
As an example, we show a chart illustrating the require- ments of the FT protocol in Figure 2. This figure shows a timeline of events on the primary and backup VMs. The arrows going from the primary line to the backup line rep- resent the transfer of log entries, and the arrows going from the backup line to the primary line represent acknowledg- ments. Information on asynchronous events, inputs, and output operations must be sent to the backup as log entries and acknowledged. As illustrated in the figure, an output to the external world is delayed until the primary VM has re- ceived an acknowledgment from the backup VM that it has received the log entry associated with the output operation. Given that the Output Rule is followed, the backup VM will be able to take over in a state consistent with the primary’s last output.
作为示例,我们在图2中展示了一张图表,用于说明FT(Fault Tolerance,容错)协议的需求。这张图展示了主虚拟机(VM)和备份VM上事件的时间线。从主线条指向备份线条的箭头代表日志条目的传输,而从备份线条指向主线条的箭头则代表确认信息。关于异步事件、输入和输出操作的信息必须作为日志条目发送到备份,并得到确认。如图所示,向外部世界的输出会被延迟,直到主VM接收到备份VM对其已接收与该输出操作相关的日志条目的确认。只要遵循输出规则,备份VM就能在与主VM最后输出状态一致的状态下接管工作。
We cannot guarantee that all outputs are produced ex- actly once in a failover situation. Without the use of trans- actions with two-phase commit when the primary intends to send an output, there is no way that the backup can determine if a primary crashed immediately before or after sending its last output. Fortunately, the network infrastruc- ture (including the common use of TCP) is designed to deal with lost packets and identical (duplicate) packets. Note that incoming packets to the primary may also be lost dur- ing a failure of the primary and therefore won’t be delivered to the backup. However, incoming packets may be dropped for any number of reasons unrelated to server failure, so the network infrastructure, operating systems, and applications are all written to ensure that they can compensate for lost packets.
在故障转移情况下,我们不能保证所有输出都能精确无误地仅产生一次。如果不使用两阶段提交事务,当主服务器打算发送一个输出时,备份服务器无法确定主服务器是在发送最后一个输出之前还是之后立即出现崩溃的。幸运的是,网络基础设施(包括常用的TCP协议)设计用于处理丢失的数据包和重复(相同)的数据包。需要注意的是,在主服务器发生故障期间,传入主服务器的数据包也可能会丢失,因此无法传递给备份服务器。但是,由于与服务器故障无关的各种原因,传入数据包可能被丢弃,因此网络基础设施、操作系统和应用程序都是为了确保它们能够补偿丢失的数据包而编写的。
2.3 Detecting and Responding to Failure
As mentioned above, the primary and backup VMs must respond quickly if the other VM appears to have failed. If the backup VM fails, the primary VM will go live – that is, leave recording mode (and hence stop sending entries on the logging channel) and start executing normally. If the primary VM fails, the backup VM should similarly go live, but the process is a bit more complex. Because of its lag in execution, the backup VM will likely have a number of log entries that it has received and acknowledged, but have not yet been consumed because the backup VM hasn’t reached the appropriate point in its execution yet. The backup VM must continue replaying its execution from the log entries until it has consumed the last log entry. At that point, the backup VM will stop replaying mode and start executing as a normal VM. In essence, the backup VM has been promoted to the primary VM (and is now missing a backup VM). Since it is no longer a backup VM, the new primary VM will now produce output to the external world when the guest OS does output operations. During the transition to normal mode, there may be some device-specific operations needed to allow this output to occur properly. In particular, for the purposes of networking, VMware FT automatically advertises the MAC address of the new primary VM on the network, so that physical network switches will know on what server the new primary VM is located. In addition, the newly promoted primary VM may need to reissue some disk IOs (as described in Section 3.4).
如上所述,主虚拟机(VM)和备份 VM 必须在另一台 VM 显现故障时迅速作出响应。如果备份 VM 发生故障,主 VM 将会“上线”——即离开记录模式(从而停止向日志通道发送条目),并开始正常执行。如果主 VM 发生故障,备份 VM 也应类似地“上线”,但这一过程更为复杂。由于备份 VM 执行存在延迟,它可能已经接收并确认了一系列日志条目,但由于尚未到达其执行过程中的适当位置,因此这些条目尚未被处理。在这种情况下,备份 VM 必须继续通过日志条目回放其执行过程,直到消耗完最后一个日志条目。此时,备份 VM 将停止回放模式,并开始作为正常 VM 执行。实质上,备份 VM 已经升级为主 VM(现在缺少了一个备份 VM)。由于不再是备份 VM,新的主 VM 现在将在客户操作系统进行输出操作时,对外部世界产生输出。在转换到正常模式的过程中,可能需要进行一些特定于设备的操作以确保输出正常进行。特别是为了网络功能,VMware FT 会自动在网络中广播新主 VM 的 MAC 地址,以便物理网络交换机知道新主 VM 位于哪台服务器上。此外,新晋升为主 VM 可能需要重新发出一些磁盘 I/O 操作(如第 3.4 节所述)。
There are many possible ways to attempt to detect failure of the primary and backup VMs. VMware FT uses UDP heartbeating between servers that are running fault-tolerant VMs to detect when a server may have crashed. In addition, VMware FT monitors the logging traffic that is sent from the primary to the backup VM and the acknowledgments sent from the backup VM to the primary VM. Because of regular timer interrupts, the logging traffic should be regular and never stop for a functioning guest OS. Therefore, a halt in the flow of log entries or acknowledgments could indicate the failure of a VM. A failure is declared if heartbeating or logging traffic has stopped for longer than a specific timeout (on the order of a few seconds).
有许多可能的方法来尝试检测主虚拟机和备份虚拟机的故障。VMware FT 使用在运行容错虚拟机的服务器之间进行的UDP心跳机制,以检测服务器何时可能出现崩溃。此外,VMware FT 还会监控从主虚拟机发送到备份虚拟机的日志流量以及从备份虚拟机发送到主虚拟机的确认信息。由于定期的定时器中断,对于正常运行的客户操作系统来说,日志流量应该是有规律且永不间断的。因此,日志条目或确认信息流的停止可能表明虚拟机出现故障。如果心跳或日志流量停止的时间超过特定超时时间(大约几秒钟),则会被声明为故障。
However, any such failure detection method is susceptible to a split-brain problem. If the backup server stops receiving heartbeats from the primary server, that may indicate that the primary server has failed, or it may just mean that all network connectivity has been lost between still functioning servers. If the backup VM then goes live while the primary VM is actually still running, there will likely be data cor- ruption and problems for the clients communicating with the VM. Hence, we must ensure that only one of the primary or backup VM goes live when a failure is detected. To avoid split-brain problems, we make use of the shared storage that stores the virtual disks of the VM. When either a primary or backup VM wants to go live, it executes an atomic test- and-set operation on the shared storage. If the operation succeeds, the VM is allowed to go live. If the operation fails, then the other VM must have already gone live, so the current VM actually halts itself (“commits suicide”). If the VM cannot access the shared storage when trying to do the atomic operation, then it just waits until it can. Note that if shared storage is not accessible because of some failure in the storage network, then the VM would likely not be able to do useful work anyway because the virtual disks reside on the same shared storage. Thus, using shared storage to resolve split-brain situations does not introduce any extra unavailability.
然而,任何此类故障检测方法都容易受到“脑裂问题”的影响。如果备份服务器停止接收到主服务器的心跳信号,这可能表明主服务器已经发生故障,也可能只是意味着仍在运行的服务器之间所有网络连接均已丢失。在这种情况下,如果备份虚拟机(VM)在主虚拟机实际上仍在运行时接管服务,很可能导致数据损坏,并给与虚拟机通信的客户端带来问题。因此,我们必须确保当检测到故障时,只有主或备份虚拟机中的一个接管服务。
为了避免脑裂问题,我们利用存储虚拟机虚拟磁盘的共享存储。当主虚拟机或备份虚拟机想要接管服务时,它会在共享存储上执行原子性的测试并设置操作。如果该操作成功,则允许该虚拟机接管服务。如果操作失败,则说明另一台虚拟机已经接管了服务,因此当前虚拟机会自行停止运行(即“自杀”)。如果虚拟机在尝试执行原子性操作时无法访问共享存储,则会一直等待直到能够访问为止。
请注意,如果由于存储网络中的某些故障导致无法访问共享存储,那么虚拟机可能也无法进行有用的工作,因为虚拟磁盘位于相同的共享存储上。因此,通过使用共享存储解决脑裂状况并不会引入额外的不可用性。
One final aspect of the design is that once a failure has oc- curred and one of the VMs has gone live, VMware FT auto- matically restores redundancy by starting a new backup VM on another host. Though this process is not covered in most previous work, it is fundamental to making fault-tolerant VMs useful and requires careful design. More details are given in Section 3.1.
设计方案的最后一个方面是,一旦发生故障并且其中一个VM(虚拟机)已经启动运行,VMware FT会自动通过在另一台主机上启动新的备份VM来恢复冗余。尽管这一过程在大多数先前的研究中并未涉及,但它对于实现容错虚拟机的实际效用至关重要,并且需要精心设计。更多详细信息将在第3.1节给出。
3. PRACTICAL IMPLEMENTATION OF FT
Section 2 described our fundamental design and protocols for FT. However, to create a usable, robust, and automatic system, there are many other components that must be de- signed and implemented.
第二节描述了我们基础的设计以及 FT 协议。然而,为了创建一个有用的、健壮的以及自动化的系统,有许多其他组件必须设计实现。
3.1 Starting and Restarting FT VMs
One of the biggest additional components that must be designed is the mechanism for starting a backup VM in the same state as a primary VM. This mechanism will also be used when re-starting a backup VM after a failure has oc- curred. Hence, this mechanism must be usable for a running primary VM that is in an arbitrary state (i.e. not just start- ing up). In addition, we would prefer that the mechanism does not significantly disrupt the execution of the primary VM, since that will affect any current clients of the VM.
需要设计的最大附加组件之一是启动与主 VM 处于相同状态的备份 VM 的机制。该机制也会在故障发生后重新启动备份 VM 时使用。因此,此机制必须适用于处于任意状态(即不仅仅是启动过程)的运行中的主 VM。此外,我们更希望该机制不会对主 VM 的执行造成显著干扰,因为这将影响当前连接到该 VM 的任何客户端。
For VMware FT, we adapted the existing VMotion func- tionality of VMware vSphere. VMware VMotion [10] allows the migration of a running VM from one server to another server with minimal disruption – VM pause times are typ- ically less than a second. We created a modified form of VMotion that creates an exact running copy of a VM on a remote server, but without destroying the VM on the local server. That is, our modified FT VMotion clones a VM to a remote host rather than migrating it. The FT VMotion also sets up a logging channel, and causes the source VM to enter logging mode as the primary, and the destination VM to enter replay mode as the new backup. Like normal VMotion, FT VMotion typically interrupts the execution of the primary VM by less than a second. Hence, enabling FT on a running VM is an easy, non-disruptive operation.
对于VMware FT,我们借鉴了VMware vSphere中已有的VMotion功能。VMware VMotion[10]允许在几乎无中断的情况下将运行中的虚拟机(VM)从一台服务器迁移到另一台服务器,通常VM暂停时间小于一秒。我们创建了一种VMotion的改进形式,它能在远程服务器上精确地创建一个正在运行的VM副本,但不会破坏本地服务器上的VM。也就是说,我们改进后的_FT VMotion_不是迁移VM,而是将其克隆到远程主机上。FT VMotion同时还会建立一个日志通道,并使源VM进入主节点的日志记录模式,目标VM则作为新的备份进入重放模式。与常规VMotion类似,FT VMotion通常也会使主VM的执行中断时间少于一秒。因此,在运行中的VM上启用FT是一项简单且无干扰的操作。
Another aspect of starting a backup VM is choosing a server on which to run it. Fault-tolerant VMs run in a cluster of servers that have access to shared storage, so all VMs can typically run on any server in the cluster. This flexibility al- lows VMware vSphere to restore FT redundancy even when one or more servers have failed. VMware vSphere imple- ments a clustering service that maintains management and resource information. When a failure happens and a primary VM now needs a new backup VM to re-establish redundancy, the primary VM informs the clustering service that it needs a new backup. The clustering service determines the best server on which to run the backup VM based on resource usage and other constraints and invokes an FT VMotion to create the new backup VM. The result is that VMware FT typically can re-establish VM redundancy within minutes of a server failure, all without any noticeable interruption in the execution of a fault-tolerant VM.
启动备份虚拟机(VM)的另一方面是选择在其上运行的服务器。容错虚拟机在一个具有共享存储访问权限的服务器集群中运行,因此所有虚拟机通常可以在集群中的任何服务器上运行。这种灵活性使得 VMware vSphere 即使在一台或多台服务器发生故障时也能恢复容错冗余。
VMware vSphere 实现了一种集群服务,用于维护管理和资源信息。当发生故障且主虚拟机现在需要新的备份虚拟机来重新建立冗余时,主虚拟机会通知集群服务它需要一个新的备份。集群服务根据资源使用情况和其他约束条件确定运行备份虚拟机的最佳服务器,并调用 FT VMotion 来创建新的备份虚拟机。
结果是,VMware FT 通常能够在服务器故障后的几分钟内重新建立虚拟机冗余,而且在整个过程中,容错虚拟机的执行不会出现明显的中断。
3.2 Managing the Logging Channel
There are a number of interesting implementation details in managing the traffic on the logging channel. In our im- plementation, the hypervisors maintain a large buffer for logging entries for the primary and backup VMs. As the primary VM executes, it produces log entries into the log buffer, and similarly, the backup VM consumes log entries from its log buffer. The contents of the primary’s log buffer are flushed out to the logging channel as soon as possible, and log entries are read into the backup’s log buffer from the logging channel as soon as they arrive. The backup sends ac- knowledgments back to the primary each time that it reads some log entries from the network into its log buffer. These acknowledgments allow VMware FT to determine when an output that is delayed by the Output Rule can be sent. Fig- ure 3 illustrates this process.
在管理日志通道上的流量时,存在许多有趣的实现细节。在我们的实现中,虚拟机监控程序为 primary 和 backup VM 维护了一个大型缓冲区,用于存储日志条目。随着 primary VM 执行,它会产生日志条目并写入日志缓冲区;同样地,backup VM 从其日志缓冲区消费日志条目。一旦可能,primary 的日志缓冲区内容就会被冲刷到日志通道上,而日志条目一到达便会从日志通道读取到备份的 log 缓冲区中。每次备份 VM 从网络读取一些日志条目到其日志缓冲区时,都会向 primary 发送确认信息。这些确认信息使得 VMware FT 能够确定何时可以发送因输出规则而延迟的输出。图3展示了这一过程。
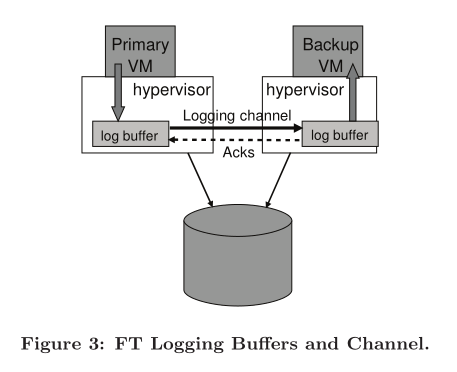
If the backup VM encounters an empty log buffer when it needs to read the next log entry, it will stop execution until a new log entry is available. Since the backup VM is not communicating externally, this pause will not affect any clients of the VM. Similarly, if the primary VM encounters a full log buffer when it needs to write a log entry, it must stop execution until log entries can be flushed out. This stop in execution is a natural flow-control mechanism that slows down the primary VM when it is producing log entries at too fast a rate. However, this pause can affect clients of the VM, since the primary VM will be completely stopped and unresponsive until it can log its entry and continue execution. Therefore, our implementation must be designed to minimize the possibility that the primary log buffer fills up.
如果备份VM在需要读取下一个日志条目时遇到空的日志缓冲区,它将停止执行,直到有新的日志条目可用。由于备份VM没有进行外部通信,因此这个暂停不会影响任何VM的客户端。类似地,如果主VM在需要写入日志条目时遇到已满的日志缓冲区,则必须停止执行,直到日志条目可以被刷新。这种执行的暂停是一种自然的流控制机制,在主VM生成日志条目的速度过快时会减慢其速度。但是,这种暂停可能会影响VM的客户端,因为在主VM能够记录其条目并继续执行之前,它会被完全停止且无法响应。因此,我们的实现设计必须尽量减少主日志缓冲区填满的可能性。
One reason that the primary log buffer may fill up is be- cause the backup VM is executing too slowly and therefore consuming log entries too slowly. In general, the backup VM must be able to replay an execution at roughly the same speed as the primary VM is recording the execution. Fortu- nately, the overhead of recording and replaying in VMware deterministic replay is roughly the same. However, if the server hosting the backup VM is heavily loaded with other VMs (and hence overcommitted on resources), the backup VM may not be able to get enough CPU and memory resources to execute as fast as the primary VM, despite the best efforts of the backup hypervisor’s VM scheduler.
主日志缓冲区可能填满的一个原因是备份虚拟机执行速度过慢,因此消耗日志条目的速度也过慢。通常情况下,备份虚拟机必须能够以大致与主虚拟机记录执行相同的速度重放执行过程。幸运的是,在VMware确定性重放中,记录和重放的开销大致是相同的。然而,如果承载备份虚拟机的服务器上还运行着大量其他虚拟机(因此资源过度分配),尽管备份管理程序的虚拟机调度器做出了最大努力,备份虚拟机可能仍无法获得足够的CPU和内存资源来与主虚拟机一样快速地执行。
Beyond avoiding unexpected pauses if the log buffers fill up, there is another reason why we don’t wish the execution lag to become too large. If the primary VM fails, the backup VM must “catch up” by replaying all the log entries that it has already acknowledged before it goes live and starts communicating with the external world. The time to finish replaying is basically the execution lag time at the point of the failure, so the time for the backup to go live is roughly equal to the failure detection time plus the current execution lag time. Hence, we don’t wish the execution lag time to be large (more than a second), since that will add significant time to the failover time.
除了避免在日志缓冲区填满时出现意外停顿外,我们不希望执行滞后变得过大的另一个原因是:如果主虚拟机(VM)出现故障,备份VM必须通过重播它已经确认的所有日志条目来“追赶”。完成重播所需的时间基本上就是故障发生时的执行滞后时间,因此备份VM上线所需的时间大致等于故障检测时间加上当前执行滞后时间。因此,我们不希望执行滞后时间过长(超过一秒),因为这会导致故障转移时间显著增加。
Therefore, we have an additional mechanism to slow down the primary VM to prevent the backup VM from getting too far behind. In our protocol for sending and acknowledg- ing log entries, we send additional information to determine the real-time execution lag between the primary and backup VMs. Typically the execution lag is less than 100 millisec- onds. If the backup VM starts having a significant execution lag (say, more than 1 second), VMware FT starts slowing down the primary VM by informing the scheduler to give it a slightly smaller amount of the CPU (initially by just a few percent). We use a slow feedback loop, which will try to gradually pinpoint the appropriate CPU limit for the primary VM that will allow the backup VM to match its execution. If the backup VM continues to lag behind, we continue to gradually reduce the primary VM’s CPU limit. Conversely, if the backup VM catches up, we gradually in- crease the primary VM’s CPU limit until the backup VM returns to having a slight lag.
因此,我们有一种额外机制来减慢主虚拟机的速度,以防止备份虚拟机落后太多。在我们的日志条目发送和确认协议中,我们会发送附加信息以确定主虚拟机和备份虚拟机之间的实时执行延迟。通常情况下,执行延迟小于100毫秒。如果备份虚拟机开始出现明显的执行延迟(比如超过1秒),VMware FT 会通过通知调度器减少其CPU使用量(最初只减少几个百分点)来减慢主虚拟机的速度。我们采用慢速反馈循环,尝试逐渐精确地找到适合主虚拟机的CPU限制,以便备份虚拟机能与其保持一致的执行速度。如果备份虚拟机继续落后,我们将逐步降低主虚拟机的CPU限制。相反,如果备份虚拟机赶上了进度,我们将逐渐增加主虚拟机的CPU限制,直到备份虚拟机恢复到略有延迟的状态。
Note that such slowdowns of the primary VM are very rare, and typically happen only when the system is under extreme stress. All the performance numbers of Section 5 include the cost of any such slowdowns.
请注意,主 VM 的这种减速很少见,通常只在系统处于低压力时发生。第 5 节的所有性能编号包括任何此类放缓的成本。
3.3 Operation on FT VMs
Another practical matter is dealing with the various con- trol operations that may be applied to the primary VM. For example, if the primary VM is explicitly powered off, the backup VM should be stopped as well, and not attempt to go live. As another example, any resource management change on the primary (such as increased CPU share) should also be applied to the backup. For these kind of operations, special control entries are sent on the logging channel from the primary to the backup, in order to effect the appropriate operation on the backup.
另一个实际问题是如何处理可能应用于主虚拟机的各种控制操作。例如,如果主虚拟机被明确地关闭,备份虚拟机也应随之停止运行,而不尝试转为活跃状态。再举一个例子,对主虚拟机进行任何资源管理更改(如增加CPU份额)也应该应用于备份虚拟机。对于这类操作,会通过日志通道从主虚拟机向备份虚拟机发送特殊的控制条目,以便在备份虚拟机上执行相应操作。
In general, most operations on the VM should be initiated only on the primary VM. VMware FT then sends any necessary control entry to cause the appropriate change on the backup VM. The only operation that can be done independently on the primary and backup VMs is VMotion. That is, the primary and backup VMs can be VMotioned independently to other hosts. Note that VMware FT ensures that neither VM is moved to the server where the other VM is, since that situation would no longer provide fault tolerance.
总的来说,对虚拟机(VM)的大多数操作应仅在主 VM 上启动。然后,VMware FT 会发送任何必要的控制条目,以在备份 VM 上引起适当的变化。可以在主 VM 和备份 VM 上独立执行的唯一操作是 VMotion。也就是说,主 VM 和备份 VM 可以独立地通过 VMotion 移动到其他主机上。请注意,VMware FT 确保两个 VM 都不会移动到对方所在的服务器上,因为这种情况将不再提供容错能力。
VMotion of a primary VM adds some complexity over a normal VMotion, since the backup VM must disconnect from the source primary and re-connect to the destination primary VM at the appropriate time. VMotion of a backup VM has a similar issue, but adds an additional complexity. For a normal VMotion, we require that all outstanding disk IOs be quiesced (i.e. completed) just as the final switchover on the VMotion occurs. For a primary VM, this quiescing is easily handled by waiting until the physical IOs complete and delivering these completions to the VM. However, for a backup VM, there is no easy way to cause all IOs to be completed at any required point, since the backup VM must replay the primary VM’s execution and complete IOs at the same execution point. The primary VM may be running a workload in which there are always disk IOs in flight during normal execution. VMware FT has a unique method to solve this problem. When a backup VM is at the final switchover point for a VMotion, it requests via the logging channel that the primary VM temporarily quiesce all of its IOs. The backup VM’s IOs will then naturally be quiesced as well at a single execution point as it replays the primary VM’s execution of the quiescing operation.
VMotion迁移主虚拟机时,相较于普通VMotion会增加一些复杂性,因为在适当的时间点,备份虚拟机需要从源主虚拟机断开连接并重新连接到目标主虚拟机。备份虚拟机的VMotion也同样存在类似问题,但还增加了额外的复杂性。
对于普通的VMotion操作,我们要求在VMotion完成最终切换时,所有未完成的磁盘I/O必须被静默(即完成)。对于主虚拟机来说,这一静默过程相对容易处理,只需等到物理I/O完成并将这些完成状态传递给虚拟机即可。
然而,对于备份虚拟机来说,在任何所需时刻都无法轻易地确保所有I/O都能完成,因为备份虚拟机需要重放主虚拟机的执行过程,并在同一执行点完成I/O。主虚拟机可能运行着一种工作负载,其中在正常执行期间始终有磁盘I/O处于活跃状态。
VMware FT为此提供了一种独特的解决方案。当备份虚拟机到达VMotion的最终切换点时,它将通过日志通道请求主虚拟机暂时静默所有的I/O。这样一来,随着备份虚拟机重放主虚拟机对静默操作的执行过程,其自身的I/O也会在一个单一执行点自然地静默完成。
3.4 Implementation Issues for Disk IOs
There are a number of subtle implementation issues re- lated to disk IO. First, given that disk operations are non- blocking and so can execute in parallel, simultaneous disk operations that access the same disk location can lead to non-determinism. Also, our implementation of disk IO uses DMA directly to/from the memory of the virtual machines, so simultaneous disk operations that access the same mem- ory pages can also lead to non-determinism. Our solution is generally to detect any such IO races (which are rare), and force such racing disk operations to execute sequentially in the same way on the primary and backup.
在磁盘输入输出方面存在一些微妙的实现问题。首先,考虑到磁盘操作是非阻塞的,因此可以并行执行,同时对同一磁盘位置进行访问的磁盘操作可能导致非确定性结果。另外,我们实现的磁盘输入输出直接使用DMA(直接内存存取)与虚拟机的内存进行数据交换,因此同时访问相同内存页的磁盘操作也可能导致非确定性结果。我们的解决方案通常是检测此类输入输出竞争情况(虽然这种情况很少发生),并在主服务器和备份服务器上以相同的方式强制这些竞争的磁盘操作顺序执行。
Second, a disk operation can also race with a memory ac- cess by an application (or OS) in a VM, because the disk operations directly access the memory of a VM via DMA. For example, there could be a non-deterministic result if an application/OS in a VM is reading a memory block at the same time a disk read is occurring to that block. This situ- ation is also unlikely, but we must detect it and deal with it if it happens. One solution is to set up page protection tem- porarily on pages that are targets of disk operations. The page protections result in a trap if the VM happens to make an access to a page that is also the target of an outstanding disk operation, and the VM can be paused until the disk operation completes. Because changing MMU protections on pages is an expensive operation, we choose instead to use bounce buffers. A bounce buffer is a temporary buffer that has the same size as the memory being accessed by a disk operation. A disk read operation is modified to read the specified data to the bounce buffer, and the data is copied to guest memory only as the IO completion is delivered. Simi- larly, for a disk write operation, the data to be sent is first copied to the bounce buffer, and the disk write is modified to write data from the bounce buffer. The use of the bounce buffer can slow down disk operations, but we have not seen it cause any noticeable performance loss.
其次,磁盘操作也可能与虚拟机(VM)中应用程序(或操作系统)的内存访问产生竞争,因为磁盘操作通过DMA直接访问VM的内存。例如,如果VM中的应用程序/操作系统在读取某个内存块的同时,该块正在进行磁盘读取操作,可能会导致非确定性的结果。这种情况虽然不太可能发生,但我们必须检测到并妥善处理。一种解决方案是在作为磁盘操作目标的页面上临时设置页面保护。当VM碰巧访问同时又是未完成磁盘操作目标的页面时,页面保护会导致陷阱,并且可以暂停VM直到磁盘操作完成。但由于更改MMU对页面的保护是一项昂贵的操作,我们选择使用_回弹缓冲区_(bounce buffer)。回弹缓冲区是一种临时缓冲区,其大小与磁盘操作所访问的内存大小相同。对于磁盘读取操作,会将其修改为将指定数据读取到回弹缓冲区中,然后仅在IO完成时将数据复制到客户机内存中。类似地,对于磁盘写入操作,需要发送的数据首先被复制到回弹缓冲区中,然后将磁盘写入操作修改为从回弹缓冲区写入数据。使用回弹缓冲区可能会降低磁盘操作的速度,但在实际应用中,我们并未观察到它造成任何明显的性能损失。
Third, there are some issues associated with disk IOs that are outstanding (i.e. not completed) on the primary when a failure happens, and the backup takes over. There is no way for the newly-promoted primary VM to be sure if the disk IOs were issued to the disk or completed successfully. In addition, because the disk IOs were not issued externally on the backup VM, there will be no explicit IO completion for them as the newly-promoted primary VM continues to run, which would eventually cause the guest operating system in the VM to start an abort or reset procedure. We could send an error completion that indicates that each IO failed, since it is acceptable to return an error even if the IO completed successfully. However, the guest OS might not respond well to errors from its local disk. Instead, we re-issue the pending IOs during the go-live process of the backup VM. Because we have eliminated all races and all IOs specify directly which memory and disk blocks are accessed, these disk operations can be re-issued even if they have already completed suc- cessfully (i.e. they are idempotent).
第三,当主服务器出现故障且备份服务器接管时,与尚未完成(即未完成)的磁盘IO相关的问题也随之出现。新晋升为主服务器的虚拟机无法确定这些磁盘IO是否已成功发送到磁盘或已完成。此外,由于备份虚拟机上并未从外部发出这些磁盘IO,在新晋升为主服务器的虚拟机继续运行的过程中,将不会为它们显示明确的IO完成情况,这最终会导致虚拟机内部的操作系统启动中止或重置程序。我们本可以发送错误完成信号,表明每个IO操作都失败了,因为即使IO已经成功完成,返回错误也是可接受的。然而,来宾操作系统可能无法很好地应对来自其本地磁盘的错误。因此,我们在备份虚拟机的上线过程中重新发出待处理的IO。由于我们已经消除了所有竞态条件,并且所有IO都明确指定了要访问的内存和磁盘块,即使这些磁盘操作已经成功完成(即它们具有幂等性),也可以重新发出这些磁盘操作。
3.5 Implementation Issues for Network IO
VMware vSphere provides many performance optimiza- tions for VM networking. Some of these optimizations are based on the hypervisor asynchronously updating the state of the virtual machine’s network device. For example, re- ceive buffers can be updated directly by the hypervisor while the VM is executing. Unfortunately these asynchronous updates to a VM’s state add non-determinism. Unless we can guarantee that all updates happen at the same point in the instruction stream on the primary and the backup, the backup’s execution can diverge from that of the primary.
VMware vSphere为虚拟机网络提供了许多性能优化措施。其中一些优化是基于虚拟化管理程序异步更新虚拟机网络设备状态的方式实现的。例如,即使在虚拟机执行期间,虚拟化管理程序也可以直接更新接收缓冲区。然而不幸的是,这些对虚拟机状态的异步更新会引入不确定性。除非我们能确保在主节点和备份节点的指令流中的同一位置进行所有更新操作,否则备份节点的执行可能会偏离主节点。
The biggest change to the networking emulation code for FT is the disabling of the asynchronous network optimiza- tions. The code that asynchronously updates VM ring buffers with incoming packets has been modified to force the guest to trap to the hypervisor, where it can log the updates and then apply them to the VM. Similarly, code that nor- mally pulls packets out of transmit queues asynchronously is disabled for FT, and instead transmits are done through a trap to the hypervisor (except as noted below).
对于FT,网络仿真代码的最大改动在于禁用了异步网络优化。原本用于异步更新VM环形缓冲区中接收到的数据包的代码已被修改,现在会强制来宾陷入到虚拟机监控程序,在那里可以记录这些更新,然后将它们应用到VM。类似地,通常异步从发送队列中提取数据包的代码在FT功能下被禁用,取而代之的是通过陷入到虚拟机监控程序的方式进行传输(除非下文另有说明)。
The elimination of the asynchronous updates of the net- work device combined with the delaying of sending pack- ets described in Section 2.2 has provided some performance challenges for networking. We’ve taken two approaches to improving VM network performance while running FT. First, we implemented clustering optimizations to reduce VM traps and interrupts. When the VM is streaming data at a suffi- cient bit rate, the hypervisor can do one transmit trap per group of packets and, in the best case, zero traps, since it can transmit the packets as part of receiving new packets. Like- wise, the hypervisor can reduce the number of interrupts to the VM for incoming packets by only posting the interrupt for a group of packets.
网络设备异步更新的消除,结合第2.2节中描述的延迟发送数据包的方式,给网络性能带来了一些挑战。在运行FT时,我们采取了两种方法来改进VM(虚拟机)网络性能。首先,我们实施了集群优化策略以减少VM陷阱和中断。当VM以足够高的比特率进行数据流传输时,hypervisor(虚拟机监控器)可以对一组数据包执行一次传输陷阱操作,在最佳情况下甚至可以实现零陷阱,因为它可以在接收新数据包的过程中同时发送这些数据包。同样,hypervisor可以通过仅针对一组数据包发布中断的方式来减少VM接收到的数据包所需的中断次数。
Our second performance optimization for networking in- volves reducing the delay for transmitted packets. As noted earlier, the hypervisor must delay all transmitted packets until it gets an acknowledgment from the backup for the ap- propriate log entries. The key to reducing the transmit delay is to reduce the time required to send a log message to the backup and get an acknowledgment. Our primary optimiza- tions in this area involve ensuring that sending and receiv- ing log entries and acknowledgments can all be done without any thread context switch. The VMware vSphere hypervisor allows functions to be registered with the TCP stack that will be called from a deferred-execution context (similar to a tasklet in Linux) whenever TCP data is received. This allows us to quickly handle any incoming log messages on the backup and any acknowledgments received by the primary without any thread context switches. In addition, when the primary VM enqueues a packet to be transmitted, we force an immediate log flush of the associated output log entry (as described in Section 2.2) by scheduling a deferred-execution context to do the flush.
我们的第二个网络性能优化措施是减少传输数据包的延迟。如前所述,虚拟机监控程序必须延迟所有待发送的数据包,直到它从备份处收到对应日志条目的确认。降低发送延迟的关键在于减少向备份发送日志消息并获取确认所需的时间。在这个领域的首要优化措施包括确保发送和接收日志条目及确认都能在不进行线程上下文切换的情况下完成。
VMware vSphere 虚拟机监控程序允许函数注册到 TCP 堆栈中,当接收到 TCP 数据时,这些函数会从延迟执行上下文(类似于 Linux 中的任务单元)调用。这样,我们就能在无需任何线程上下文切换的情况下快速处理备份上的任何传入日志消息以及主节点接收到的任何确认信息。
此外,当主虚拟机将数据包排队等待发送时,我们会通过调度一个延迟执行上下文来立即刷新相关的输出日志条目(如第 2.2 节所述),从而强制立即刷新日志,以确保关联的数据包能够尽快发送。
4. DESIGN ALTERNATIVES
In our implementation of VMware FT, we have explored a number of interesting design alternatives. In this section, we explore some of these alternatives.
在我们 VMware FT 的实现中,我们已经探索了许多有趣的替代设计。在这节中,我们探索一些替代设计。
4.1 Shared vs. Non-shared Disk
In our default design, the primary and backup VMs share the same virtual disks. Therefore, the content of the shared disks is naturally correct and available if a failover occurs. Essentially, the shared disk is considered external to the pri- mary and backup VMs, so any write to the shared disk is considered a communication to the external world. There- fore, only the primary VM does actual writes to the disk, and writes to the shared disk must be delayed in accordance with the Output Rule.
在我们默认的设计中,主虚拟机和备份虚拟机会共享相同的虚拟磁盘。因此,如果发生故障转移,共享磁盘的内容自然会是正确且可用的。本质上,共享磁盘被认为是主虚拟机和备份虚拟机外部的资源,所以对共享磁盘的任何写入都被视为对外部世界的通信。因此,只有主虚拟机执行实际的磁盘写入操作,并且必须按照输出规则延迟对共享磁盘的写入操作。

An alternative design is for the primary and backup VMs to have separate (non-shared) virtual disks. In this design, the backup VM does do all disk writes to its virtual disks, and in doing so, it naturally keeps the contents of its virtual disks in sync with the contents of the primary VM’s virtual disks. Figure 4 illustrates this configuration. In the case of non-shared disks, the virtual disks are essentially considered part of the internal state of each VM. Therefore, disk writes of the primary do not have to be delayed according to the Output Rule. The non-shared design is quite useful in cases where shared storage is not accessible to the primary and backup VMs. This may be the case because shared storage is unavailable or too expensive, or because the servers running the primary and backup VMs are far apart (“long-distance FT”). One disadvantage of the non-shared design is that the two copies of the virtual disks must be explicitly synced up in some manner when fault tolerance is first enabled. In addition, the disks can get out of sync after a failure, so they must be explicitly resynced when the backup VM is restarted after a failure. That is, FT VMotion must not only sync the running state of the primary and backup VMs, but also their disk state.
另一种设计方案是主虚拟机和备份虚拟机拥有各自独立(非共享)的虚拟磁盘。在这种设计中,备份虚拟机会将其所有磁盘写操作都记录到其自身的虚拟磁盘上,在此过程中,它会自然地保持自身虚拟磁盘内容与主虚拟机虚拟磁盘内容的一致性。图4展示了这一配置。对于非共享磁盘的情况,虚拟磁盘实质上被视为每个虚拟机内部状态的一部分。因此,主虚拟机的磁盘写操作无需按照输出规则进行延迟。在无法访问共享存储或者共享存储不可用或成本过高的情况下,以及主虚拟机和备份虚拟机运行于相距较远(“远距离FT”)的服务器上的场景下,非共享设计非常有用。然而,非共享设计的一个缺点是:当首次启用容错功能时,必须以某种方式显式同步两份虚拟磁盘的内容。此外,在发生故障后,磁盘可能会出现不同步的情况,所以在备份虚拟机在故障后重启时,需要显式重新同步它们。也就是说,FT VMotion不仅需要同步主虚拟机和备份虚拟机的运行状态,还需要同步它们的磁盘状态。
In the non-shared-disk configuration, there may be no shared storage to use for dealing with a split-brain situa- tion. In this case, the system could use some other external tiebreaker, such as a third-party server that both servers can talk to. If the servers are part of a cluster with more than two nodes, the system could alternatively use a majority al- gorithm based on cluster membership. In this case, a VM would only be allowed to go live if it is running on a server that is part of a communicating sub-cluster that contains a majority of the original nodes.
在非共享磁盘配置中,可能没有可用于处理脑裂情况的共享存储。这种情况下,系统可以使用其他外部决胜机制,例如两台服务器都能通信的第三方服务器。如果服务器是拥有两个以上节点的集群的一部分,系统则可以选择基于集群成员资格的多数决算法作为替代方案。在这种情况下,虚拟机只有在其运行在包含原始节点中大多数节点的通信子集群内的服务器上时,才允许上线运行。
4.2 Executing Disk Reads on the Backup VM
In our default design, the backup VM never reads from its virtual disk (whether shared or non-shared). Since the disk read is considered an input, it is natural to send the results of the disk read to the backup VM via the logging channel.
An alternate design is to have the backup VM execute disk reads and therefore eliminate the logging of disk read data. This approach can greatly reduce the traffic on the logging channel for workloads that do a lot of disk reads. However, this approach has a number of subtleties. It may slow down the backup VM’s execution, since the backup VM must execute all disk reads and wait if they are not physically completed when it reaches the point in the VM execution where they completed on the primary.
在我们的默认设计方案中,备份虚拟机从不读取其虚拟磁盘(无论是共享的还是非共享的)中的数据。由于磁盘读取被视为输入操作,因此自然会通过日志通道将磁盘读取的结果发送给备份虚拟机。
另一种设计方案是让备份虚拟机执行磁盘读取操作,从而消除对磁盘读取数据的记录。这种方法可以极大地减少对大量进行磁盘读取的工作负载的日志通道上的流量。然而,这种方法存在一些微妙之处。它可能会减慢备份虚拟机的执行速度,因为在执行过程中,当备份虚拟机到达与主虚拟机完成磁盘读取操作相同的时间点时,如果物理层面尚未完成读取,备份虚拟机必须执行所有磁盘读取并等待。
Also, some extra work must be done to deal with failed disk read operations. If a disk read by the primary succeeds but the corresponding disk read by the backup fails, then the disk read by the backup must be retried until it succeeds, since the backup must get the same data in memory that the primary has. Conversely, if a disk read by the primary fails, then the contents of the target memory must be sent to the backup via the logging channel, since the contents of memory will be undetermined and not necessarily replicated by a successful disk read by the backup VM.
Finally, there is a subtlety if this disk-read alternative is used with the shared disk configuration. If the primary VM does a read to a particular disk location, followed fairly soon by a write to the same disk location, then the disk write must be delayed until the backup VM has executed the first disk read. This dependence can be detected and handled correctly, but adds extra complexity to the implementation.
另外,还需要额外的工作来处理磁盘读取操作失败的情况。如果主节点成功读取了磁盘,而备份节点对相应磁盘的读取却失败了,则备份节点必须重试该磁盘读取操作直至成功,因为备份节点必须获取与主节点相同的内存数据。反之,如果主节点的磁盘读取失败,则目标内存中的内容必须通过日志通道发送给备份节点,因为在这种情况下,内存中的内容是不确定的,并不一定能通过备份VM成功的磁盘读取进行复制。
最后,在使用共享磁盘配置时,这种磁盘读取替代方案存在一个微妙之处。如果主VM首先从某个磁盘位置执行读取操作,随后很快又对该同一磁盘位置进行写入操作,则磁盘写入操作必须延迟,直到备份VM完成首次磁盘读取操作。这种依赖关系可以被检测到并正确处理,但这无疑会增加实现过程的复杂性。
In Section 5.1, we give some performance results indicat- ing that executing disk reads on the backup can cause some slightly reduced throughput (1-4%) for real applications, but can also reduce the logging bandwidth noticeably. Hence, executing disk reads on the backup VM may be useful in cases where the bandwidth of the logging channel is quite limited.
在5.1节中,我们提供了一些性能结果,表明在备份上执行磁盘读取可能会对实际应用的吞吐量造成轻微降低(1-4%),但同时也能明显减少日志记录带宽。因此,在备份虚拟机上执行磁盘读取可能在日志记录通道带宽非常有限的情况下具有实用性。
5. PERFORMANCE EVALUATION
In this section, we do a basic evaluation of the performance of VMware FT for a number of application workloads and networking benchmarks. For these results, we run the pri- mary and backup VMs on identical servers, each with eight Intel Xeon 2.8 Ghz CPUs and 8 Gbytes of RAM. The servers are connected via a 10 Gbit/s crossover network, though as will be seen in all cases, much less than 1 Gbit/s of network bandwidth is used. Both servers access their shared virtual disks from an EMC Clariion connected through a standard 4 Gbit/s Fibre Channel network. The client used to drive some of the workloads is connected to the servers via a 1 Gbit/s network.
在本节中,我们对VMware FT在多个应用程序工作负载和网络基准测试方面的性能进行了基本评估。为了得出这些结果,我们在相同的服务器上运行主虚拟机(VM)和备份VM,每台服务器配置了8个Intel Xeon 2.8 Ghz CPU和8 GB内存。服务器通过10 Gbit/s交叉网络相互连接,但正如所有案例所示,实际使用的网络带宽远小于1 Gbit/s。两台服务器都通过标准的4 Gbit/s光纤通道网络连接到EMC Clariion,以访问它们共享的虚拟磁盘。用于驱动部分工作负载的客户端是通过1 Gbit/s网络连接到服务器的。
The applications that we evaluate in our performance re- sults are as follows. SPECJbb2005 is an industry-standard Java application benchmark that is very CPU- and memory- intensive and does very little IO. Kernel Compile is a work- load that runs a compilation of the Linux kernel. This work- load does some disk reads and writes, and is very CPU- and MMU-intensive, because of the creation and destruction of many compilation processes. Oracle Swingbench is a work- load in which an Oracle 11g database is driven by the Swing- bench OLTP (online transaction processing) workload. This workload does substantial disk and networking IO, and has eighty simultaneous database sessions. MS-SQL DVD Store is a workload in which a Microsoft SQL Server 2005 database is driven by the DVD Store benchmark, which has sixteen simultaneous clients.
在我们的性能结果中评估的应用程序包括以下几项:
-
SPECJbb2005是一款行业标准的Java应用基准测试工具,对CPU和内存资源要求极高,且几乎不涉及IO操作。
-
Kernel Compile是一个运行Linux内核编译的工作负载。由于创建和销毁大量编译进程的原因,此工作负载会进行一些磁盘读写操作,并且对CPU和MMU(内存管理单元)的使用非常密集。
-
Oracle Swingbench是一个由Swingbench OLTP(在线事务处理)工作负载驱动的Oracle 11g数据库的工作负载。该工作负载涉及到大量的磁盘和网络IO,并同时支持80个并发数据库会话。
-
MS-SQL DVD Store是一个由DVD Store基准测试驱动的Microsoft SQL Server 2005数据库的工作负载,其中包含16个并发客户端。
5.1 Basic Performance Results
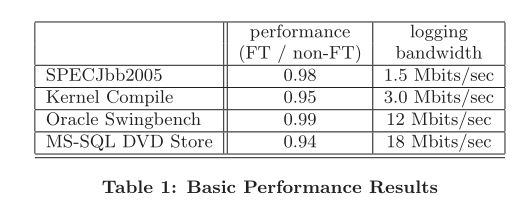
Table 1 gives basic performance results. For each of the applications listed, the second column gives the ratio of the performance of the application when FT is enabled on the VM running the server workload vs. the performance when FT is not enabled on the same VM. The performance ra- tios are calculated so that a value less than 1 indicates that the FT workload is slower. Clearly, the overhead for en- abling FT on these representative workloads is less than 10%. SPECJbb2005 is completely compute-bound and has no idle time, but performs well because it has minimal non- deterministic events beyond timer interrupts. The other workloads do disk IO and have some idle time, so some of the FT overhead may be hidden by the fact that the FT VMs have less idle time. However, the general conclusion is that VMware FT is able to support fault-tolerant VMs with a quite low performance overhead.
表 1 列出了基本的性能结果。对于每个应用程序,第二列给出了应用程序的性能比例,运行服务器工作负载的虚拟机上启用和未启用FT的情况。性能比小于 1 表示带FT的工作负载更慢。显然,这些有代表性的工作负载上启用FT 的开销小于10%。 SPECJbb2005 完全受计算限制,没有空闲时间,但其表现性能良好,因为它具有最小的除定时器中断以外的不确定性事件。另一个工作负载做磁盘 IO 有一些空闲时间,所以一些 FT 开销可能被 FT虚拟机的空闲时间更少的真实情况隐藏。然而,一般的结论是 VMware FT 能够支持故障容忍 VM,并且具备相当低的性能开销。
In the third column of the table, we give the average band- width of data sent on the logging channel when these appli- cations are run. For these applications, the logging band- width is quite reasonable and easily satisfied by a 1 Gbit/s network. In fact, the low bandwidth requirements indicate that multiple FT workloads can share the same 1 Gbit/s network without any negative performance effects.
在表的第三列中,我们给出了当应用程序正在运行时,在日志通道上发送数据的平均带宽。对于这些应用程序,日志带宽相当合理,1 Gbit/s 的网络就能满足 。事实上,低带宽要求表明多个 FT 工作负载可以共享相同的 1 Gbit/s 网络,同时没有任何负面的性能影响。
For VMs that run common guest operating systems like Linux and Windows, we have found that the typical logging bandwidth while the guest OS is idle is 0.5-1.5 Mbits/sec. The “idle” bandwidth is largely the result of recording the delivery of timer interrupts. For a VM with an active work- load, the logging bandwidth is dominated by the network and disk inputs that must be sent to the backup – the net- work packets that are received and the disk blocks that are read from disk. Hence, the logging bandwidth can be much higher than those measured in Table 1 for applications that have very high network receive or disk read bandwidth. For these kinds of applications, the bandwidth of the logging channel could be a bottleneck, especially if there are other uses of the logging channel.
对于运行常见操作系统的 VM,例如 Linux 和 Windows,我们发现当操作系统空闲时,通常的日志记录带宽为 0.5-1.5 Mbits/sec。"空闲"带宽主要是记录定时器中断发送的结果。对于具有活动中工作负载的 VM 而言,日志带宽由网络和必须发送到备份的磁盘输入主导—网络收到的数据包和从磁盘读取的磁盘块。因此,对于非常高的网络接收或者磁盘读取带宽的应用而言,日志带宽高于表1中的测量值。对于这类应用而言,日志通道的带宽可能是瓶颈,特别是日志通道还有其他使用时。
The relatively low bandwidth needed over the logging channel for many real applications makes replay-based fault tolerance very attractive for a long-distance configuration using non-shared disks. For long-distance configurations where the primary and backup might be separated by 1-100 kilometers, optical fiber can easily support bandwidths of 100-1000 Mbit/s with latencies of less than 10 milliseconds. For the applications in Table 1, a bandwidth of 100-1000 Mbit/s should be sufficient for good performance. Note, however, that the extra round-trip latency between the pri- mary and backup may cause network and disk outputs to be delayed by up to 20 milliseconds. The long-distance configu- ration will only be appropriate for applications whose clients can tolerate such an additional latency on each request.
对于许多实际应用程序而言,日志记录所需的带宽相对较低,这使得基于重放的故障容忍对于使用非共享磁盘的长距离配置非常有吸引力。对于远距离配置而言,其主备VM可能相隔 1-100 公里,光纤可以轻松地支持延迟小于 10 毫秒的 100-1000 Mbit/s 带宽。对于表 1 中的应用而言,主备之间的额外往返延迟,可能会导致网络和磁盘输出最多延迟 20 毫秒。远距离配置仅适用于这类应用程序:他的客户端可以容忍每个请求的额外延迟。
For the two most disk-intensive applications, we have mea- sured the performance impact of executing disk reads on the backup VM (as described in Section 4.2) vs. sending disk read data over the logging channel. For Oracle Swingbench, throughput is about 4% lower when executing disk reads on the backup VM; for MS-SQL DVD Store, throughput is about 1% lower. Meanwhile, the logging bandwidth is de- creased from 12 Mbits/sec to 3 Mbits/sec for Oracle Swing- bench, and from 18 Mbits/sec to 8 Mbits/sec for MS-SQL DVD Store. Clearly, the bandwidth savings could be much greater for applications with much greater disk read band- width. As mentioned in Section 4.2, it is expected that the performance might be somewhat worse when disk reads are executed on the backup VM. However, for cases where the bandwidth of the logging channel is limited (for example, a long-distance configuration), executing disk reads on the backup VM may be useful.
对于两个最占用磁盘空间的应用程序,我们测量了在备份 VM上执行磁盘读取(如第 4.2 节所述)与通过日志记录通道发送磁盘读取数据相比,对于性能的影响。对于 Oracle Swingbench 来说,在备份 VM 上执行磁盘读取时的吞吐量降低约 4%;对于 MS-SQL DVD 存储,吞吐量约降低 1%。同时,Oracle Swingbench 的日志带宽从 12 Mbits/sec 降低到 3 Mbits/sec,MS-SQL DVD 存储从 18 Mbits/sec 降低到 8 Mbits/sec。显然,对于具有更大磁盘读取带宽的应用程序,带宽可能会节省很多。如第 4.2 节所述,预计在备份 VM 上执行磁盘读取时,性能可能会更差。但是,对于日志通道的带宽是有限的(例如,远程配置)情况下,在备份 VM 上执行磁盘读取可能有用。
5.2 Network Benchmarks
Networking benchmarks can be quite challenging for our system for a number of reasons. First, high-speed network- ing can have a very high interrupt rate, which requires the logging and replaying of asynchronous events at a very high rate. Second, benchmarks that receive packets at a high rate will cause a high rate of logging traffic, since all such packets must be sent to the backup via the logging channel. Third, benchmarks that send packets will be subject to the Output Rule, which delays the sending of network packets until the appropriate acknowledgment from the backup is received. This delay will increase the measured latency to a client. This delay could also decrease network bandwidth to a client, since network protocols (such as TCP) may have to decrease the network transmission rate as the round-trip latency increases.
出于多种原因。网络基准测试对我们的系统来说非常具有挑战性。第一,高速网络会有一个非常高的中断率,这需要以非常高的速度记录和重放异步事件。 第二,以高速率接收数据包的基准将导致高速率的日志流量,因为所有这些数据包必须通过日志通道发送到备份。第三,发送数据包的基准测试将受制于输出规则,延迟网络数据包的发送直到已收到来自备份VM的确认。 此延迟会增加对客户端测量的延迟。这种延迟还可能会降低到客户端的网络带宽,因为网络协议(如 TCP)由于往返延迟增加,可能不得不降低网络传输速率。

Table 2 gives our results for a number of measurements made by the standard netperf benchmark. In all these mea- surements, the client VM and primary VM are connected via a 1 Gbit/s network. The first two rows give send and re- ceive performance when the primary and backup hosts are connected by a 1 Gbit/s logging channel. The third and fourth rows give the send and receive performance when the primary and backup servers are connected by a 10 Gbit/s logging channel, which not only has higher bandwidth, but also lower latency than the 1 Gbit/s network. As a rough measure, the ping time between hypervisors for the 1 Gbit/s connection is about 150 microseconds, while the ping time for a 10 Gbit/s connection is about 90 microseconds.
表 2 给出了我们通过标准的 netperf 基准测试,多次测量的结果。在所有这些测量中,客户端 VM 和主 VM 通过 1 Gbit/s 网络连接。前两行给出了主备主机间通过 1 Gbit/s 的日志通道连接时,发送和接收的性能。第三行和第四行给出当主备服务器通过 10 Gbit/s 的日志通道连接时,发送和接收的性能,不仅带宽更高,延迟也低于 1 Gbit/s。作为一个粗略的测量,在 1 Gbit/s 网络连接的管理程序之间, ping 时间约为 150 微秒,而对于 10 Gbit/s 连接,ping 时间大约需要 90 微秒。
When FT is not enabled, the primary VM can achieve close (940 Mbit/s) to the 1 Gbit/s line rate for transmits and receives. When FT is enabled for receive workloads, the logging bandwidth is very large, since all incoming network packets must be sent on the logging channel. The logging channel can therefore become a bottleneck, as shown for the results for the 1 Gbit/s logging network. The effect is much less for the 10 Gbit/s logging network. When FT is enabled for transmit workloads, the data of the transmitted packets is not logged, but network interrupts must still be logged. The logging bandwidth is much lower, so the achievable net- work transmit bandwidths are higher than the network re- ceive bandwidths. Overall, we see that FT can limit network bandwidths significantly at very high transmit and receive rates, but high absolute rates are still achievable.
未启用 FT 时,主 VM 对于接收和发送,可以实现接近 (940 Mbit/s) 1 Gbit/s 的线路传输速率。当为接收工作负载启用 FT 时,日志记录带宽非常大,因为所有传入的网络数据包必须在日志通道上发送。因此,日志记录通道可能成为瓶颈,正如 1 Gbit/s 日志网络的结果。对于 10 Gbit/s 的日志网络,影响则小了很多。当为上传工作负载启用 FT 时,上传数据包的数据不会记录,但仍必须记录网络中断。日志带宽要低得多,因此可实现的网络上传带宽高于网络接收带宽。总的来说,我们看到 FT 在非常高的上传和接收速率情况下,可以显著地限制网络带宽,但仍然可以实现很高的速率。
6. RELATED WORK
Bressoud and Schneider [3] described the initial idea of im- plementing fault tolerance for virtual machines via software contained completely at the hypervisor level. They demon- strated the feasibility of keeping a backup virtual machine in sync with a primary virtual machine via a prototype for servers with HP PA-RISC processors. However, due to lim- itations of the PA-RISC architecture, they could not imple- ment fully secure, isolated virtual machines. Also, they did not implement any method of failure detection or attempt to address any of the practical issues described in Section 3. More importantly, they imposed a number of constraints on their FT protocol that were unnecessary. First, they im- posed a notion of epochs, where asynchronous events are delayed until the end of a set interval. The notion of an epoch is unnecessary – they may have imposed it because they could not replay individual asynchronous events effi- ciently enough. Second, they required that the primary VM stop execution essentially until the backup has received and acknowledged all previous log entries. However, only the output itself (such as a network packet) must be delayed – the primary VM itself may continue executing.
[3]中的Bressoud和Schneider首次提出了在完全位于虚拟机监控器层级的软件中实现虚拟机容错性的初始构想。他们通过一个针对HP PA-RISC处理器服务器的原型展示了保持备份虚拟机与主虚拟机同步的可行性。然而,由于PA-RISC架构的局限性,他们无法实现完全安全、隔离的虚拟机。此外,他们并未实现任何故障检测方法,也没有尝试解决第3节中描述的任何实际问题。更重要的是,他们在FT协议中施加了一些不必要的限制。
首先,他们引入了“时代(epochs)”的概念,在这个概念下,异步事件会被延迟到设定时间间隔结束时执行。时代概念其实是不必要的——他们可能是因为无法高效地重播单个异步事件而强制引入这一概念。其次,他们要求主虚拟机在备份虚拟机接收到并确认所有先前日志条目之前,实质上必须停止执行。然而,实际上只需输出本身(如网络数据包)被延迟,主虚拟机自身可以继续执行。
Bressoud [4] describes a system that implements fault tol- erance in the operating system (Unixware), and therefore provides fault tolerance for all applications that run on that operating system. The system call interface becomes the set of operations that must be replicated deterministically. This work has similar limitations and design choices as the hypervisor-based work.
Bressoud[4]描述了一个在操作系统(Unixware)中实现容错性的系统,因此为该操作系统上运行的所有应用程序提供了容错能力。系统调用接口成为必须确定性地复制的一组操作。这项工作与基于虚拟机监控器的工作具有类似的局限性和设计选择。
Napper et al. [9] and Friedman and Kama [7] describe im- plementations of fault-tolerant Java virtual machines. They follow a similar design to ours in sending information about inputs and non-deterministic operations on a logging chan- nel. Like Bressoud, they do not appear to focus on detecting failure and re-establishing fault tolerance after a failure. In addition, their implementation is limited to providing fault tolerance for applications that run in a Java virtual machine. These systems attempt to deal with issues of multi-threaded Java applications, but require either that all data is cor- rectly protected by locks or enforce a serialization on access to shared memory.
Napper 等人[9]和 Friedman 和 Kama[7] 描述了容错 Java 虚拟机的实现。他们的设计与我们相似,通过日志通道发送关于输入和非确定性操作的信息。与 Bressoud 一样,他们似乎并未专注于检测故障以及在故障后重新建立容错能力。此外,他们的实现仅限于为在 Java 虚拟机中运行的应用程序提供容错保护。这些系统试图处理多线程 Java 应用程序的问题,但要求所有数据要么正确使用锁进行保护,要么强制执行对共享内存的序列化访问。
Dunlap et al. [6] describe an implementation of determin- istic replay targeted towards debugging application software on a paravirtualized system. Our work supports arbitrary operating systems running inside virtual machines and im- plements fault tolerance support for these VMs, which re- quires much higher levels of stability and performance.
Dunlap 等人在参考文献[6]中描述了一种针对在Para虚拟化系统上调试应用程序软件的确定性重放实现。我们的工作支持在虚拟机内部运行的各种操作系统,并为这些虚拟机实现了容错支持,这就需要更高的稳定性和性能水平。
Cully et al. [5] describe an alternative approach for sup- porting fault-tolerant VMs and its implementation in a proj- ect called Remus. With this approach, the state of a pri- mary VM is repeatedly checkpointed during execution and sent to a backup server, which collects the checkpoint infor- mation. The checkpoints must be executed very frequently (many times per second), since external outputs must be delayed until a following checkpoint has been sent and ac- knowledged. The advantage of this approach is that it ap- plies equally well to uni-processor and multi-processor VMs.
[5]中,Cully等人描述了一种用于支持容错虚拟机(VM)的替代方法及其在名为Remus的项目中的实现。该方法中,在主虚拟机执行过程中,其状态会不断进行检查点记录并发送至备份服务器,备份服务器负责收集这些检查点信息。由于外部输出必须延迟到下一个检查点已发送并得到确认后才能进行,因此要求检查点执行的频率非常高(每秒多次)。这种方法的优势在于,它同样适用于单处理器和多处理器虚拟机环境。
The main issue is that this approach has very high network bandwidth requirements to send the incremental changes to memory state at each checkpoint. The results for Remus presented in [5] show 100% to 225% slowdown for kernel compile and SPECweb benchmarks, when attempting to do 40 checkpoints per second using a 1 Gbit/s network connec- tion for transmitting changes in memory state. There are a number of optimizations that may be useful in decreas- ing the required network bandwidth, but it is not clear that reasonable performance can be achieved with a 1 Gbit/s connection. In contrast, our approach based on determin- istic replay can achieve less than 10% overhead, with less than 20 Mbit/s bandwidth required between the primary and backup hosts for several real applications.
主要问题是,该方法需要非常高的网络带宽来在每个检查点时发送内存状态的增量更改。[5]中展示的Remus在尝试使用1 Gbit/s网络连接每秒进行40次检查点以传输内存状态变化时,对于内核编译和SPECweb基准测试显示了100%到225%的性能下降。有许多可用于减少所需网络带宽的优化技术,但尚不清楚是否能够通过1 Gbit/s连接实现合理的性能。相比之下,我们基于确定性重放的方法可以实现低于10%的开销,在主服务器和备份主机之间对几个实际应用所需的带宽少于20 Mbit/s。
7. CONCLUSION AND FUTURE WORK
We have designed and implemented an efficient and com- plete system in VMware vSphere that provides fault tol- erance (FT) for virtual machines running on servers in a cluster. Our design is based on replicating the execution of a primary VM via a backup VM on another host using VMware deterministic replay. If the server running the pri- mary VM fails, the backup VM takes over immediately with no interruption or loss of data.
Overall, the performance of fault-tolerant VMs under VM- ware FT on commodity hardware is excellent, and shows less than 10% overhead for some typical applications. Most of the performance cost of VMware FT comes from the overhead of using VMware deterministic replay to keep the primary and backup VMs in sync. The low overhead of VMware FT therefore derives from the efficiency of VMware deterministic replay. In addition, the logging bandwidth re- quired to keep the primary and backup in sync is typically quite small, often less than 20 Mbit/s. Because the log- ging bandwidth is quite small in most cases, it seems fea- sible to implement configurations where the primary and backup VMs are separated by long distances (1-100 kilome- ters). Thus, VMware FT could be used in scenarios that also protect against disasters in which entire sites fail. It is worthwhile to note that the log stream is typically quite com- pressible, and simple compression techniques can decrease the logging bandwidth significantly with a small amount of extra CPU overhead.
Our results with VMware FT have shown that an efficient implementation of fault-tolerant VMs can be built upon de- terministic replay. Such a system can transparently provide fault tolerance for VMs running any operating systems and applications with minimal overhead. However, for a system of fault-tolerant VMs to be useful for customers, it must also be robust, easy-to-use, and highly automated. A usable system requires many other components beyond replicated execution of VMs. In particular, VMware FT automatically restores redundancy after a failure, by finding an appropriate server in the local cluster and creating a new backup VM on that server. By addressing all the necessary issues, we have demonstrated a system that is usable for real applications in customer’s datacenters.
我们已经在VMware vSphere中设计并实现了一个高效且完整的系统,该系统为运行在集群服务器上的虚拟机提供了故障容忍(FT)功能。我们的设计方案基于使用VMware确定性重播技术,在另一台主机上的备份虚拟机上复制主虚拟机的执行过程。如果运行主虚拟机的服务器发生故障,备份虚拟机将立即接管,不会出现中断或数据丢失的情况。
总体而言,在商用硬件上,使用VMware FT的容错虚拟机性能优异,对于某些典型应用其开销小于10%。VMware FT的大部分性能损耗源于采用VMware确定性重播保持主、备份虚拟机同步所产生的额外开销。因此,VMware FT的低开销主要源自VMware确定性重播的高效性。此外,保持主、备份虚拟机同步所需的日志带宽通常相当小,通常低于20 Mbit/s。由于大多数情况下所需日志带宽很小,因此实现主、备份虚拟机相隔较远距离(1-100公里)的配置是可行的。这意味着VMware FT可以应用于同时防止整个站点灾难性故障的场景。
我们对VMware FT的研究结果表明,通过确定性重播可以构建出高效实现容错功能的虚拟机系统。这样的系统能够以最小的额外开销透明地为运行任何操作系统和应用程序的虚拟机提供故障容忍能力。然而,为了让容错虚拟机系统真正对客户有用,它还必须具备鲁棒性、易用性和高度自动化等特点。一个可用的系统除了需要复制虚拟机执行外,还需要许多其他组件。特别是,VMware FT能够自动在本地集群中找到合适的服务器,并在该服务器上创建新的备份虚拟机,从而在故障后恢复冗余。通过解决所有必要的问题,我们已经展示了一个适用于客户数据中心真实应用的可用系统。
One of tradeoffs with implementing fault tolerance via de- terministic replay is that currently deterministic replay has only been implemented efficiently for uni-processor VMs. However, uni-processors VMs are more than sufficient for a wide variety of workloads, especially since physical pro- cessors are continually getting more powerful. In addition, deterministic replay can still provide significant benefits for workloads that do not require multiprocessor VMs. Therefore, while there may be some limitations in implementing fault tolerance via deterministic replay, it is still a valuable approach for many use cases. In addition, many workloads can be scaled out by using many uni-processor VMs instead of scaling up by using one larger multi-processor VM. High-performance replay for multi-processor VMs is an active area of research, and can potentially be enabled with some extra hardware support in microprocessors. One interesting direction might be to extend transactional memory models to facilitate multi-processor replay.
In the future, we are also interested in extending our sys- tem to deal with partial hardware failure. By partial hard- ware failure, we mean a partial loss of functionality or re- dundancy in a server that doesn’t cause corruption or loss of data. An example would be the loss of all network connec- tivity to the VM, or the loss of a redundant power supply in the physical server. If a partial hardware failure occurs on a server running a primary VM, in many cases (but not all) it would be advantageous to fail over to the backup VM immediately. Such a failover could immediately restore full service for a critical VM, and ensure that the VM is quickly moved off of a potentially unreliable server.
在通过确定性重放实现容错的过程中,其中一个权衡之处在于,目前确定性重放仅能高效地应用于单处理器虚拟机(VM)。然而,对于广泛的工作负载而言,单处理器虚拟机已经足够强大,特别是考虑到物理处理器的性能正在不断提升。此外,即使对于那些不需要多处理器虚拟机的工作负载,确定性重放仍然可以提供显著的优势。因此,虽然通过确定性重放实现容错可能存在一些局限性,但对于许多应用场景来说,它仍然是一个有价值的方案。另外,许多工作负载可以通过使用多个单处理器虚拟机进行横向扩展,而不是通过使用单一更大的多处理器虚拟机进行纵向扩展。对于多处理器虚拟机的高性能重放是一个活跃的研究领域,有可能通过微处理器中的一些额外硬件支持来实现。
未来,我们还对将系统扩展以处理部分硬件故障感兴趣。所谓部分硬件故障,是指服务器中出现的部分功能丧失或冗余损失,并不会导致数据损坏或丢失。例如,虚拟机所有网络连接的丢失,或者是物理服务器中冗余电源的损失。如果运行主虚拟机的服务器发生部分硬件故障,在很多情况下(但并非所有情况),立即切换到备份虚拟机是具有优势的。这种故障转移能够立即为关键虚拟机恢复全面服务,并确保虚拟机迅速从可能不可靠的服务器上迁移出去。
Acknowledgments
We would like to thank Krishna Raja, who generated many of the performance results. There were numerous people involved in the implementation of VMware FT. Core implementors of deterministic replay, (including support for a variety of virtual devices) and the base FT functional- ity included Lan Huang, Eric Lowe, Slava Malyugin, Alex Mirgorodskiy, Kaustubh Patil, Boris Weissman, Petr Van- drovec, and Min Xu. In addition, there are many other people involved in the higher-level management of FT in VMware vCenter. Karyn Ritter did an excellent job man- aging much of the work.
我们要感谢 Krishna Raja,他做出了许多性能结果。在 VMware FT 实现中有许多人参与。确定性重放的核心实现者(包括对各种虚拟设备的支持)和基本 FT 功能的实现者包括 Lan Huang、Eric Lowe、Slava Malyugin、Alex Mirgorodskiy、Kaustubh Patil、Boris Weissman、Petr Vandrovec 和 Min Xu。此外,在 VMware vCenter 中管理 FT 的高级管理层也有许多人员参与。Karyn Ritter 在管理大部分工作方面做得非常出色。
8. REFERENCES
- Alsberg, P., and Day, J. A Principle for Resilient Sharing of Distributed Resources. In Proceedings of the Second International Conference on Software Engineering (1976), pp. 627–644.
- AMD Corporation. AMD64 Architecture Programmer’s Manual. Sunnyvale, CA.
- Bressoud, T., and Schneider, F. Hypervisor-based Fault Tolerance. In Proceedings of SOSP 15 (Dec. 1995).
- Bressoud, T. C. TFT: A Software System for Application-Transparent Fault Tolerance. In Proceedings of the Twenty-Eighth Annual International Symposium on Fault-Tolerance Computing (June 1998), pp. 128–137.
- Cully, B., Lefebvre, G., Meyer, D., Feeley, M., Hutchison, N., and Warfield, A. Remus: High Availability via Asynchronous Virtual Machine Replication. In Proceedings of the Fifth USENIX Symposium on Networked Systems Design and Implementation (Apr. 2008), pp. 161–174.
- Dunlap, G. W., King, S. T., Cinar, S., Basrai, M., and Chen, P. M. ReVirt: Enabling Intrusion Analysis through Virtual Machine Logging and Replay. In Proceedings of the 2002 Symposium on Operating Systems Design and Implementation (Dec. 2002).
- Friedman, R., and Kama, A. Transparent Fault-Tolerant Java Virtual Machine. In Proceedings of Reliable Distributed System (Oct. 2003), pp. 319–328.
- Intel Corporation. IntelAˆ R 64 and IA-32 Architectures Software Developer’s Manuals. Santa Clara, CA.
- Napper, J., Alvisi, L., and Vin, H. A Fault-Tolerant Java Virtual Machine. In Proceedings of the International Conference on Dependable Systems and Networks (June 2002), pp. 425–434.
- Nelson, M., Lim, B.-H., and Hutchins, G. Fast Transparent Migration for Virtual Machines. In Proceedings of the 2005 Annual USENIX Technical Conference (Apr. 2005).
- Nightingale, E. B., Veeraraghavan, K., Chen, P. M., and Flinn, J. Rethink the Sync. In Proceedings of the 2006 Symposium on Operating Systems Design and Implementation (Nov. 2006).
- Schlicting, R., and Schneider, F. B. Fail-stop Processors: An Approach to Designing Fault-tolerant Computing Systems. ACM Computing Surveys 1, 3 (Aug. 1983), 222–238.
- Schneider, F. B. Implementing fault-tolerance services using the state machine approach: A tutorial. ACM Computing Surveys 22, 4 (Dec. 1990), 299–319.
- Stratus Technologies. Benefit from Stratus Continuing Processing Technology: Automatic 99.999% Uptime for Microsoft Windows Server Environments. At http://www.stratus.com/˜/media/- Stratus/Files/Resources/WhitePapers/continuous- processing-for-windows.pdf, June 2009.
- Xu, M., Malyugin, V., Sheldon, J., Venkitachalam, G., and Weissman, B. ReTrace: Collecting Execution Traces with Virtual Machine Deterministic Replay. In Proceedings of the 2007 Workshop on Modeling, Benchmarking, and Simulation (June 2007).